On a posé 500 questions de fact-checking à Vera, ChatGPT, Gemini et Perplexity. Résultat : 91% des sources de Vera sont des médias ou fact-checkers certifiés. Pour les autres ? Entre 12 et 22%. Gemini cite YouTube dans presque 10% de ses réponses, Perplexity s'appuie sur Reddit. Et quand Vera s'abstient faute de source fiable, les autres répondent quand même, avec des sources non certifiées. Le fact-checking par IA, c'est aussi fiable que les sources qu'on lui donne.
Répartition des sources utilisées par les LLMs en tant que fact-checkeurs
Introduction
Après un an à travailler bénévolement sur Vera, pour le compte de l’ONG LaReponse.tech, j'ai décidé de partager quelques chiffres sur les capacités des Large Language Models (LLMs par la suite) à faire du fact-checking. Depuis ses débuts, Vera - l'IA de fact checking disponible sur whatsapp, instagram et par téléphone - a reçu environ 500k messages et compte plus de 10k utilisateurs actifs mensuels.
Utilisation des LLMs par le grand public
Nos 500k messages ne sont rien comparés aux autres LLMs, chatGPT compte 700 millions d'utilisateurs actifs hebdomadaires [1] (!), Gemini 650 millions d'utilisateurs par mois et Claude atteint les 30 millions par mois [3]. On peut rajouter Perplexity qui compte au moins 10 millions d'utilisateurs actifs mensuels [4]. Bref, Vera est une molécule d'eau, même à côté du chat de Mistral qui atteint 1 million d'utilisateurs mensuel [5].
Plateforme
M d'utilisateurs actifs mensuels
ChatGPT
>700
Gemini
650
Claude
30
Perplexity
>10
Mistral
1
Vera
0.01
Avec autant d'utilisateurs et plusieurs milliards de requêtes par jour [6, 7, 8, 9], il est clair que ces outils s'ancrent de plus en plus dans nos vies. Anthropic et openAI ont même publié certains chiffres sur comment nous utilisons ces interfaces [1, 10]. D'après OpenAI 70% des requêtes sont non professionnelles, et en grande partie sur des sujets pratiques, de la recherche d'information [1].
Trois quarts des conversations portent sur des conseils pratiques, la recherche d’informations et la rédaction, cette dernière étant la tâche professionnelle la plus courante [...]. [1]
Le fact-checking entre dans ce domaine : rechercher de l'information afin de vérifier un fait, une déclaration ou un chiffre. Souvent dans un cadre privé: débats familiaux, entre amis ou lors d'évènements citoyens. Ou lorsqu'il s'agit de connaître des effets indésirables d'un médicament, de savoir si on peut se baigner après avoir mangé ou bien si le remède familial est réellement efficace. Si les LLMs sont déjà utilisés pour vérifier des faits, la question n'est plus de savoir s'ils le font, mais s'ils le font bien.
Efficacité du fact-checking
Pour que le fact checking soit influent, il est nécessaire de jouer, entre autres, sur deux aspects : le timing et la crédibilité des sources.
Deux piliers du fact checking
Sur le timing, premièrement il vaut mieux pour un utilisateur debunker une information après que celui-ci y ait été exposé plutôt qu'avant ou pendant. En effet, avoir recours au fact-checking après l’exposition permet à l'utilisateur de mieux ancrer la correction de l'information dans sa mémoire, car celle-ci agit alors comme un feedback correctif [11]. Sur un autre aspect du timing, la rapidité entre la lecture de la désinformation et le debunking est cruciale [12]. Plus le temps passe entre l'exposition à la désinformation et la lecture du debunking, plus l'information s'ancre et s'associe à l'identité de la personne. Et donc il est plus compliqué pour elle d'être sensible au contenu du fact-checking.
Pilier
Ce qui marche
Ce qu'il faut éviter
Timing
Debunker après exposition (effet feedback correctif)
Debunker avant ou pendant l'exposition
Rapidité
Intervenir le plus vite possible après l'exposition
Laisser le temps à l'info de s'ancrer et de s'associer à l'identité
Fiabilité de la source
Source perçue comme neutre et digne de confiance
Source perçue comme partiale, même si experte
Expertise de la source
Compétence reconnue dans le domaine
Expertise seule, sans fiabilité perçue (insuffisant)
Sur la crédibilité des sources, pour qu'un utilisateur soit sensible au contenu d'un fact-check, la source doit être perçue comme crédible [13]. Cette crédibilité repose sur deux dimensions : l'expertise (la compétence perçue dans le domaine) et la fiabilité (la confiance dans les intentions de la source). Entre ces deux dimensions, la fiabilité s'avère particulièrement clé : l'expertise de la source seule n'est pas suffisante pour réduire la désinformation, tandis que la fiabilité seule diminue significativement l'adhésion aux fausses informations [14].
LLMs fact-checkeurs?
Du point de vue du timing, les systèmes LLMs et les applications qui en découlent, comme Vera, sont tout à fait opportuns pour contrer la désinformation. En effet, ces dispositifs répondent de manière quasi instantanée aux utilisateurs. Ils sont utilisés pour se documenter sur une information après y avoir été exposé. Et ils permettent de minimiser le temps entre l'exposition et la correction/confirmation de celles-ci puisqu'ils peuvent résumer des montagnes d'information en un prompt.
En revanche sur la fiabilité et l'expertise des sources utilisées par les LLMs, plusieurs problèmes ont été identifiés par la recherche. Premièrement les hallucinations : certaines sources sont fabriquées par ces systèmes [15, 16, 17]. Deuxièmement, lorsque les sujets sont complexes ou moins populaires, les LLMs ont tendance à inventer davantage [15, 18]. Donc il semblerait que les LLMs soient limités pour le fact-checking, surtout si on leur laisse une liberté totale sur la citation des sources. Il faut néanmoins admettre que Les LLMs se sont améliorés sur le sujet des hallucinations [17, 19], même si le problème ne sera sûrement jamais résolu [20]. Et que les principaux fournisseurs s'attachent à citer des sources et essayent de s'assurer que celles-ci ne sont pas fabriquées. Cependant il est clair qu'il est nécessaire d'analyser les sources citées par les LLMs pour évaluer leur fiabilité puisque ce critère est une des clés de la réussite des fact-checking auprès des utilisateurs.
Les LLMs répondent vite, c'est leur force. Mais répondent-ils avec les bonnes sources ? Pour le mesurer, nous avons soumis les principaux modèles à un test systématique.
Protocole d'évaluation de fiabilité des LLMs pour le fact-checking
Dans un premier temps nous avons sélectionné 500 questions de fact-checking. Ces questions sont en Français, sur des sujets variés (politique, santé, société, agriculture...) et nous avons demandé à Vera et aux autres LLMs de répondre en citant des sources.
Est-il vrai qu’une voiture électrique est plus polluante qu’une voiture à essence si on ne roule pas beaucoup ? Est-ce vrai qu’il va y avoir des vols courts ou les passagers seront debout ? Brigitte Macron a-t-elle vraiment participé au détournement de l'argent des pièces jaunes ? Bordeaux est-elle la ville la plus dangereuse en France ? Est-ce que McDonald met des anti-vomitifs dans ces burgers ? Exemples de questions de fact-checking
Dans un second temps, nous avons reproduit les comportements des principaux fournisseurs de LLMs via leurs APIs respectives. Nous avons utilisé les API de Gemini (modèle gemini-2.5-flash-lite) et Perplexity (modèle sonar) avec leur recherche native, ainsi que celle d'OpenAI pour reproduire le comportement de chatGPT avec gpt-5.2. Et en parallèle nous avons demandé à Vera de répondre aux mêmes 500 questions.
Enfin nous étudions deux composantes clés pour la fiabilité des sources utilisées pour répondre au fact-checking:
La catégorisation des sources utilisées (académique, fact-checking, média, réseaux sociaux, etc.)
La rareté des sources mise en avant pour répondre aux questions
Nous n'explorons pas la qualité des réponses comme par exemple l'association source/réponse, ou bien l'évaluation de la qualité de la réponse elle-même, ce sera pour un autre billet. Nous nous contentons d'évaluer la fiabilité des sources, pilier de la réussite du fact-checking.
Commençons par le plus immédiat : quand ces modèles citent une source, de quel type de source s'agit-il ?
Les sources utilisées
Sur toutes les sources générées par les systèmes LLMs, nous avons analysé et catégorisé les domaines de ces sources.
Ainsi, les deux premières catégories de sources sont “Médias certifiés” et “Fact-checkers certifiés”. Tout média ou fact-checker ne disposant pas de l'un de ces labels a été classé dans une catégorie distincte : “Autres médias” ou “Autres fact-checkers”. Ce choix méthodologique est délibéré : notre comité d'experts ne conduit pas sa propre évaluation des standards journalistiques ou de fact-checking d'une source donnée. Il vérifie que celle-ci répond aux critères de reconnaissance établis par les organismes de référence (JTI, EFCSN et IFCN pour les certifications, EIC, ICIJ et Forbidden Stories pour l'appartenance à des consortiums d'investigation).
Voici quelques exemples de Médias/fact-checker certifiés ou non:
Domaine
Catégorie
Description
www.france24.com
Média certifié
Média français, journal d'information généraliste
ici.radio-canada.ca
Média certifié
Radio Canada, média public canadien international
https://www.leprogres.fr/
Média certifié
Média français, journal d'information généraliste
01net.com
Autre média
Média en ligne spécialisé dans l'actualité high-tech et numérique
huffpost.fr
Autre média
Version française du Huffington Post, actualités et opinions
konbini.com
Autre média
Média en ligne dédié à la pop culture et aux tendances
snopes.com
Fact checker certifié
Site de fact-checking depuis 1994
politifact.com
Fact checker certifié
Fact-checker américain lauréat du Prix Pulitzer
fullfact.org
Fact checker certifié
Organisation britannique indépendante de vérification des faits
adfontesmedia.com
Autre fact checker
Ad Fontes Media, évalue les biais et fiabilité des médias
hoaxbuster.com
Autre fact checker
Site français de vérification des rumeurs et hoax sur internet
captainfact.io
Autre fact checker
Plateforme collaborative de fact-checking vidéo
Exemples de classification média/fact-checker certifiés ou non
Autres sources
Les autres catégories que nous avons utilisées pour classifier les sources sont les suivantes:
Réseaux sociaux : plateformes de partage et d'échange communautaire (X, Facebook, YouTube, forums de discussion, etc.)
Académique : universités, centres de recherche, revues scientifiques, archives ouvertes et établissements d'enseignement
Encyclopédie : encyclopédies en ligne, dictionnaires et bases de connaissances collaboratives
Association : Fondations, syndicats, fédérations et organisations à but non lucratif
Entreprise : sites commerciaux, blogs d'entreprise, services en ligne, e-commerce, marketplaces et pages corporate
Blog : sites personnels, blogs d'opinion ou de passionnés sans structure éditoriale professionnelle
Autre : Toutes les sources qui n'entrent dans aucune des catégories précédentes
Domaine
Catégorie
Description
x.com
Réseaux sociaux
Réseau social de microblogging
facebook.com
Réseaux sociaux
Réseau social généraliste de Meta
youtube.com
Réseaux sociaux
Plateforme de partage de vidéos de Google
service-public.fr
Institutionnel
Portail officiel de l'administration française
who.int
Institutionnel
Organisation mondiale de la santé (OMS)
elysee.fr
Institutionnel
Site officiel de la Présidence de la République française
nature.com
Académique
Revue scientifique de référence mondiale
cnrs.fr
Académique
Centre national de la recherche scientifique
scholar.google.com
Académique
Moteur de recherche académique de Google
wikipedia.org
Encyclopédie
Encyclopédie collaborative en ligne
britannica.com
Encyclopédie
Encyclopédie de référence en ligne
larousse.fr
Encyclopédie
Dictionnaire et encyclopédie de langue française
amnesty.org
Association
ONG internationale de défense des droits humains
wwf.fr
Association
Fonds mondial pour la nature, protection environnementale
msf.fr
Association
Médecins Sans Frontières, aide humanitaire médicale
apple.com
Entreprise
Site officiel du fabricant de produits technologiques
microsoft.com
Entreprise
Site officiel de l'éditeur de logiciels
airbnb.com
Entreprise
Plateforme de location de logements entre particuliers
medium.com
Blog personnel
Plateforme de blogs et articles personnels
wordpress.com
Blog personnel
Plateforme d'hébergement de blogs personnels
substack.com
Blog personnel
Plateforme de newsletters et blogs par abonnement
archive.org
Autre
Archives numériques et Wayback Machine
bit.ly
Autre
Service de raccourcissement d'URLs
pastebin.com
Autre
Service de partage de texte en ligne
Exemples de sources et leur catégorie
Répartition des sources
Dans un premier temps regardons la répartitions des sources, cités par ces systèmes selon la taxonomie que nous avons présentée juste au dessous:
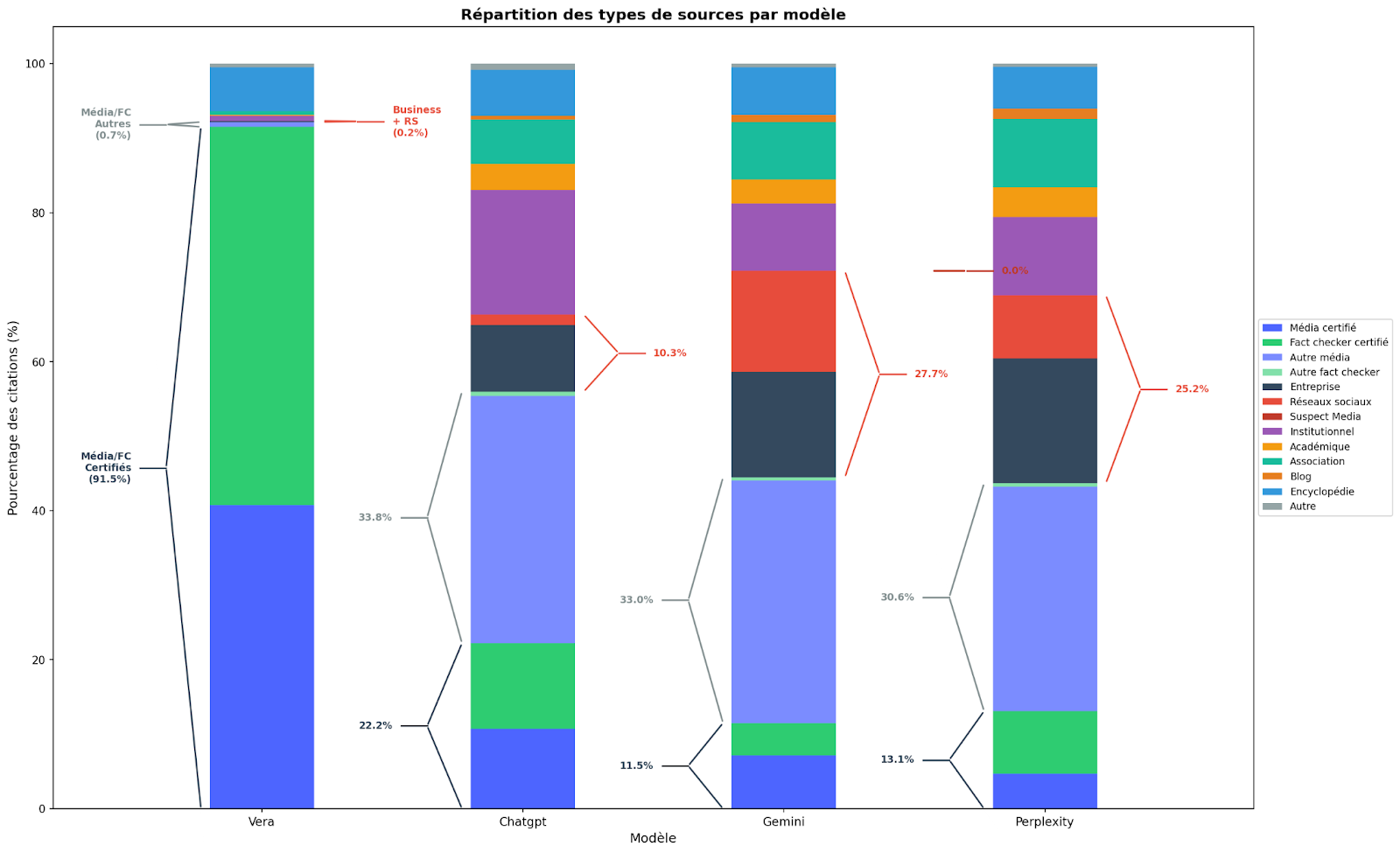
Répartition des sources utilisées par les LLMs pour fact-checker.
Le constat est assez clair, 91% des sources citées par Vera sont des médias et fact-checkeurs certifiés. C'était attendu étant donné les spécificités de Vera. Il y a pour le reste 7% de sources issues de Wikipedia, académiques ou institutionnelles. Ce qui signifie que l'on conserve environ 2% des sources qui ne sont pas certifiées. Ceci montre la difficulté à imposer des gardes fous aux LLMs, qui même contraint, peuvent citer des sources non désirées.
Lorsque l'on compare aux autres LLMs utilisés comme fact-checker, on se rend compte que chatGPT, Gemini et Perplexity citent uniquement des sources certifiées respectivement 22%, 12% et 13% du temps. La différence est immense. Même si nous considérons tous les médias et/ou fact checkers, même non certifiés, cela correspond à seulement 56% des sources citées par chatGPT, 46% pour Gemini et 44% pour Perplexity. Alors que les encyclopédies, les sources institutionnelles et académiques représentent respectivement 32%, 19% et 18%.
Le problème réside sur les autres types de sources citées par ces systèmes : 10% des sources sont issues des réseaux sociaux ou de sites commerciaux pour chatGPT, 28% pour Gemini et 25% pour Perplexity. Ce qui veut dire pour ces deux derniers utilisent au moins une source sur quatre provenant de réseaux sociaux ou de sites commerciaux afin de vous répondre sur des sujets de fact-checking. Même si moins fiable que Vera par rapport aux standards des sources mobilisées, chatGPT apparaît plus rigoureux pour le fact checking que ces deux concurrents. En effet, Gemini et Perplexity citent une proportion significativement plus élevée de sources issues de réseaux sociaux ou de sites commerciaux. Or, ces sources ne sont soumises à aucun processus de vérification indépendant, contrairement aux publications journalistiques, académiques ou institutionnelles qui respectent des standards de relecture et de transparence. Un contenu Reddit massivement upvoté ou une page produit bien référencée peuvent être factuellement exacts, mais rien dans leur mode de production ne le garantit. Et c'est précisément cette absence de garantie qui fragilise la fiabilité des réponses qui s'y adossent.
Le thème influence le type de source
De plus, cette proportion de sources issues de réseaux sociaux ou de sites commerciaux varie selon le sujet de la question de fact-checking, ce qui est loin d'être anodin. Sur les questions liées à l'économie, la part des sources commerciales augmente significativement : elle passe d'une moyenne de 8.2% à 10.9% pour ChatGPT, de 13.1% à 22.2% pour Gemini, et de 16% à 28.7% pour Perplexity. On observe une variation également sur les questions de sécurité pour la proportion de sources issues de réseaux sociaux : de 1.0% à 1.3% pour ChatGPT, de 19.2% à 26.5% pour Gemini, et de 10.5% à 12.7% pour Perplexity. Le problème est que c'est précisément sur les sujets économiques que les sources commerciales présentent les conflits d'intérêts les plus évidents. Utiliser ces sources pour vérifier des affirmations économiques revient, dans une certaine mesure, à demander aux parties prenantes d'arbitrer leur propre cause. Sur la sécurité, la tendance est symétrique : les réseaux sociaux, terrain privilégié de désinformation sécuritaire [21, 22] et de manipulation informationnelle [23, 24], voient leur poids augmenter. S'appuyer davantage sur ces sources précisément là où elles sont le plus vulnérables revient à accroître l'exposition du fact-checking aux contenus qu'il est censé corriger.
Les sites commerciaux et RS comme socle factuel
Enfin quelques chiffres intéressants sur les questions dont la réponse a mobilisé des sources commerciales ou de réseaux sociaux.
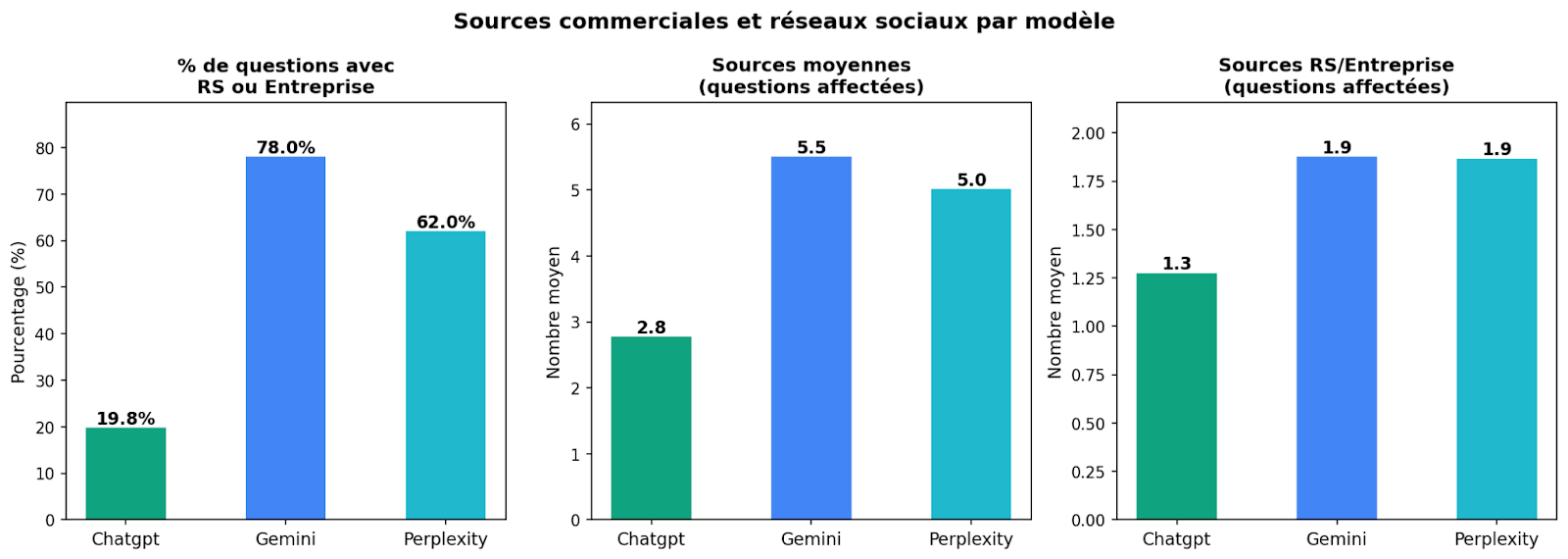
Utilisation des sources commerciales et Réseaux Sociaux par les LLMs. Le premier graphe représente le nombre de questions où les LLMs ont utilisé au moins une source commericale ou des réseaux sociaux. Le deuxième représente, pour les questions avec au moins une source commerciale ou RS, le nombre totale de sources utilisées pour répondre. Le troisième graphe donne le nombre de sources RS ou commericales en moyenne pour ces questions.
On remarque qu'environ une question sur cinq adressée à chatGPT mobilise au moins une source commerciale ou issue des réseaux sociaux (19.8%). Ce ratio est multiplié par près de quatre pour Gemini (78%) et par 3 pour Perplexity (62%). On pourrait supposer que ces sources fragiles se trouvent diluées parmi d'autres, plus rigoureuses. Les données suggèrent le contraire. Lorsqu'une question fait appel à au moins une source commerciale ou de réseau social, ces sources représentent en moyenne près de la moitié du total des sources mobilisées par ChatGPT (1.3 sur 2.8, soit 46%) et plus d’un tiers pour Gemini (1.9 sur 5.5, soit 35%) et Perplexity (1.9 sur 5.0, soit 39%). Ces proportions posent deux problèmes. D'abord la concentration : quand un LLM mobilise des sources commerciales ou de réseaux sociaux, celles-ci représentent un tiers à la moitié des références, pas une source faible noyée dans un ensemble solide, mais un bloc entier du socle factuel. Ensuite l'opacité : l'utilisateur qui voit cinq ou six liens en bas de réponse perçoit de l'abondance et de la diversité, sans moyen d'évaluer quelle proportion relève de contenus non vérifiés..
Maintenant que nous avons constaté que la fiabilité des sources par les principaux fournisseurs de LLMs peut être en grande partie remise en question pour le fact-checking, contrairement à Vera qui s’appuie plus de 9 fois sur 10 sur des sources certifiées, intéressons nous un peu plus en détail aux domaines cités par ces grands modèles de langage.
Au-delà du type de sources, une autre question se pose : ces modèles reviennent-ils vers des sources qu'ils connaissent, ou piochent-ils à chaque question dans un réservoir différent ?
Domaines utilisés
Dans cette partie, nous allons plonger un peu plus dans le détail des domaines utilisés par Vera et les autres fournisseurs de LLM.
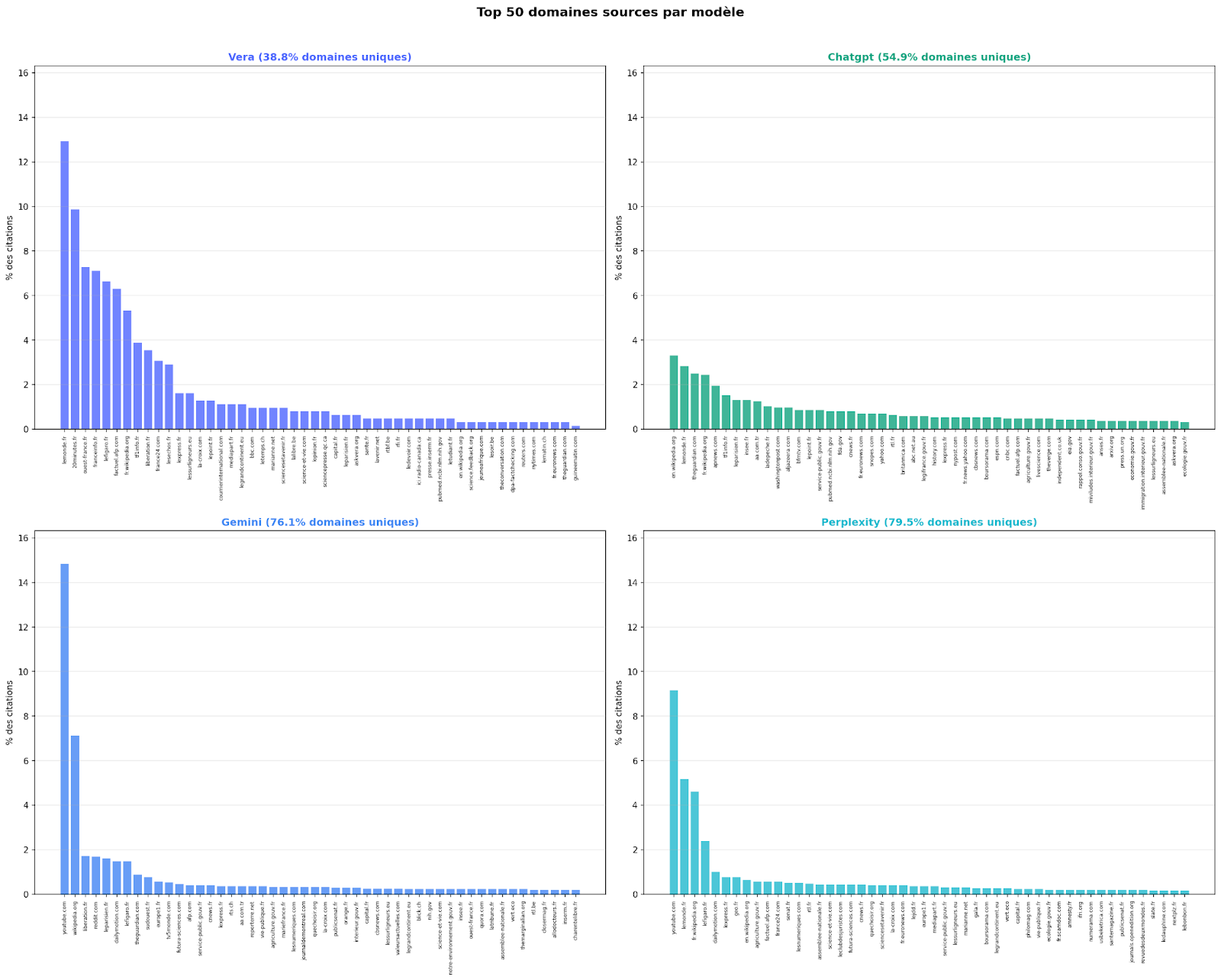
Répartition des domaines cités par les LLMs. Plus la barre est haute, plus un domaine a été cité par le LLM sur l'ensemble des questions.
Les quatre modèles présentent une distribution des sources en loi de puissance: quelques domaines concentrent l'essentiel des citations, suivis d'une longue traîne, mais avec des profils radicalement différents.
Chez Vera, la concentration des citations sur un noyau restreint de domaines reflète directement le choix méthodologique décrit plus haut : Vera utilise de manière répétée un répertoire de sources dont les standards éditoriaux ont été préalablement vérifiés via les labels JTI, EFCSN et IFCN. Cette concentration n'est pas un défaut de diversité : c'est la conséquence mécanique d'un filtrage en amont Chez Gemini et Perplexity, la concentration existe aussi, mais elle s'opère sur des sources d'une nature tout à fait différente. Les domaines les plus cités sont respectivement YouTube (~9.5%) et Reddit (~7.3%). Autrement dit, quand Vera concentre ses citations sur Le Monde ou Ouest-France, Gemini concentre les siennes sur YouTube. Le problème n'est pas la concentration en soi, mais le fait qu'elle s'exerce sur des plateformes de contenu généré par les utilisateurs, où n'importe qui peut publier sans contrôle éditorial. ChatGPT présente un profil inverse : sa courbe est la plus plate des quatre, aucun domaine ne dépassant ~3% des citations. À première vue, cela pourrait apparaître comme un signe de diversité et d'équilibre. Mais cette absence de hiérarchisation pose un problème symétrique : si aucune source ne domine, cela signifie aussi qu'il n'existe aucune priorisation stable des sources de haute qualité par rapport aux sources fragiles. Un article du Monde et un post sur un forum pèsent potentiellement de manière comparable dans la construction de la réponse. C'est d'ailleurs un problème que partagent dans une moindre mesure Gemini et Perplexity au-delà de leurs quelques sources dominantes : une fois passée la tête de distribution (YouTube, Reddit, Wikipedia), la longue traîne agrège indistinctement domaines institutionnels, blogs, sites commerciaux et forums.
Domaines uniques
Intéressons nous maintenant à la question des domaines uniques. Nous définissons un domaine unique comme un domaine source n'apparaissant qu'une seule fois sur l'ensemble des réponses 500 questions de fact-checking. Pour chaque modèle, nous avons mesuré deux indicateurs : d'abord, la proportion de domaines uniques par rapport au nombre total de domaines distincts cités ; ensuite, la part que représentent ces domaines uniques dans le volume total des citations (où chaque occurrence d'un domaine est comptabilisée individuellement).
Modèle
% domaines uniques
% de ces citations
ChatGPT
54.9
36.6
Gemini
76.1
51.8
Perplexity
79.5
60.8
Pour Vera, le taux de domaines uniques importe peu : dans la mesure où l'ensemble des sources provient d'un répertoire préalablement certifié comme fiable, qu'un domaine ne soit cité qu'une seule fois sur l’échantillon ne fragilise pas la réponse: la source a déjà été évaluée en amont. En revanche, pour les autres LLMs c’est une autre histoire. ChatGPT (54.9%), Gemini (76.1%) et Perplexity (79.5%) présentent des taux nettement plus élevés : la majorité des domaines qu'ils citent n'apparaissent qu'une seule fois dans l'ensemble du corpus. Cette « diversité » n'est pas le fruit d'une stratégie de triangulation des sources. Elle reflète le fonctionnement du moteur de recherche sous-jacent, qui remonte les résultats les mieux référencés à un instant donné, sans critère stable de qualité éditoriale. En d'autres termes : Vera fait confiance à peu de sources, mais les connaît ; les LLMs citent beaucoup de sources, mais ne les évaluent pas.
Ce taux élevé de domaines uniques a une conséquence directe sur la fiabilité : il devient impossible de garantir la qualité de sources qui, par définition, n'apparaissent qu'une fois et n'ont fait l'objet d'aucune évaluation préalable. Nos données illustrent concrètement ce risque. On trouve parmi ces domaines uniques des sources parfaitement légitimes : easa.europa.eu (l'agence européenne de sécurité aérienne) citée par ChatGPT sur une question relative à l'aviation, ou toureiffel.paris (le site officiel de la Tour Eiffel) mobilisé par Perplexity. On trouve ensuite des sources sans rapport manifeste avec la question posée. Gemini cite spectacles.carrefour.fr, la billetterie d'un supermarché, pour une question sur la carrière de Blanche Gardin. Pour vérifier si un noyau d'avocat macéré dans l'alcool constitue un remède contre les douleurs dorsales, un LLM renvoie vers fregis.com, un site vétérinaire traitant de l'intoxication du chien à l'avocat. Pour la question « les chats peuvent-ils vivre sous l'eau pendant une heure ? », une source citée est bluebuffalo.com, un site de nourriture pour animaux. Le moteur de recherche a bien identifié un champ lexical commun (avocat, chat), mais pas la pertinence réelle de la source par rapport à l'affirmation à vérifier. Plus problématique encore, certains domaines uniques orientent la réponse vers des sources dont la fiabilité est discutable : fdesouche.com, site connu pour ses contenus orientés sur l'immigration, cité par ChatGPT sur une question relative aux prénoms musulmans en France ; raw-feeding-prey-model.fr, un blog personnel sur l'alimentation crue animale datant de 2016, pour une question médicale sur une bactérie dans le saumon posée en 2025. Pour une affirmation de Marion Maréchal sur une agression, la source citée est marionmarechal.info, le propre site de la personnalité politique à l'origine de la déclaration, ce qui revient à sourcer une affirmation par la personne même qui l'a formulée. Ces exemples ne sont pas des cas extrêmes sélectionnés pour les besoins de la démonstration. Le taux élevé de domaines uniques était en soi un signal : si plus de six citations sur dix chez Perplexity renvoient vers un domaine que le modèle n'a utilisé qu'une seule fois sur tout l’échantillon, cela signifie qu'il n'existe aucun mécanisme de validation récurrente de ces sources. Donc aucune garantie sur ce que l'on y trouve. Les exemples confirment cette intuition. Ils sont la conséquence prévisible d'un système qui puise dans l'ensemble du web indexé sans filtre éditorial préalable : le moteur de recherche remonte ce qui est lexicalement pertinent et bien référencé, pas ce qui est factuellement fiable.
C'est vrai que si on découpe en morceaux le noyau d'un avocat, qu'on le met dans un bocal avec de l'alcool et qu'on laisse reposer, on obtient un remède contre les courbatures, les douleurs dorsales, articulaires ? - https://www.fregis.com/urgence/intoxication-chien-avocat-avocatier/
Les chats peuvent vivre sous l'eau pendant une heure? - https://www.bluebuffalo.com/fr-ca/accueil/chat/chat-hydratation/
Exemples de questions de fact-checking
Un système qui cite des sources fragiles est un problème. Mais un système qui cite des sources fragiles tout en prétendant toujours avoir une réponse en est un plus grand encore. C'est précisément ce qui distingue Vera : sa capacité à ne pas répondre lorsque les sources disponibles ne sont pas suffisantes pour produire une vérification fiable.
Le taux de réponse
Il arrive que Vera ne trouve pas de sources suffisantes pour répondre à une question. Cela peut se produire dans plusieurs cas de figure : lorsqu'aucune source certifiée n'a encore validé ou corrigé l'information en question ; lorsque l'actualité est trop récente pour avoir été référencée, comme ce fut le cas dans les premières heures de la tentative de coup d'État au Bénin, ou lorsqu'une fausse information se diffuse sous les radars avant d'être repérée par les médias et fact-checkers, comme nous l'avons observé cet été avec la rumeur sur Jessica Radcliffe prétendument dévorée par un orque.
Modèle
Réponse mobilisant une source
Vera
74.2% (371/500)
ChatGPT
99.0% (495/500)
Gemini
97.4% (487/500)
Perplexity
99.2% (496/500)
Sur les 500 questions de notre corpus, Vera a mobilisé des sources pour répondre dans 74,2% des cas (371 sur 500). Les trois LLMs, eux, répondent quasiment systématiquement : 99% pour ChatGPT, 97.4% pour Gemini, 99.2% pour Perplexity.
Cet écart ne traduit pas un défaut de couverture de Vera: il traduit une différence de philosophie. Lorsque Vera ne répond pas, c'est parce qu'aucune source certifiée ne permet d'étayer ou d'infirmer l'affirmation avec un niveau de confiance suffisant. Les LLMs, en revanche, trouvent presque toujours quelque chose : leur moteur de recherche remonte invariablement des résultats depuis le web indexé, et le modèle construit une réponse à partir de ce qu'il trouve. Mais comme nous l'avons vu, « trouver une source » ne signifie pas « trouver une source fiable ». Un système qui répond à 99% des questions en puisant dans un réservoir où 60 à 80% des domaines n'apparaissent qu'une seule fois, et où l'on retrouve indifféremment des agences européennes, des sites de billetterie de supermarché et des blogs personnels, ne garantit pas une meilleure couverture. Il garantit une réponse, ce qui est fondamentalement différent.
Par exemple, sur la question “Est-il vrai que l'extrême droite s'attaque aux engagements citoyens des élèves ?” Perplexity répond que “oui” et cite simplement le site `https://parce-que.fr/`. La réponse est catégorique et donne un exemple basé sur une seule source. Ou bien à la question "Les bottes de pressothérapie sont-elles vraiment efficaces ?", 4 sources sont … des sites de vendeurs de bottes… qui affirment toutes que ces bottes sont efficaces.
Savoir dire je ne sais pas
Ce comportement pose un problème pour le fact-checking. Un vérificateur d'information n'est pas un moteur de recherche : on ne mesure pas sa valeur à sa capacité à produire une réponse à chaque question, mais à la fiabilité des réponses qu'il produit via la fiabilité de ces sources comme nous l’avons vu plus haut. Or la recherche en psychologie de la crédibilité montre que la confiance accordée à une source d'information dépend moins de son assurance que de sa calibration. C’est-à-dire, la correspondance entre le niveau de certitude qu'elle exprime et la solidité réelle de ses fondements. Une étude [25] démontre expérimentalement que des informateurs systématiquement confiants perdent davantage de crédibilité lorsqu'une erreur est révélée que des informateurs qui expriment leur incertitude là où elle existe. La calibration, savoir ce que l'on sait et ce que l'on ne sait pas, s'avère un déterminant de crédibilité plus puissant que la confiance ou l'exactitude prises isolément. Plus récemment, des chercheurs ont montré dans une expérience en ligne [26] que les communicants qui signalaient l'incertitude de leurs résultats subissent une perte de confiance significativement moindre lorsque les données évoluent par la suite, comparés à ceux qui avaient présenté leurs conclusions sans réserve. Autrement dit, reconnaître les limites de ce que l'on peut affirmer ne fragilise pas la confiance: c'est au contraire ce qui la protège dans la durée. Un fact-checker qui répond à 99 % des questions sans disposer de sources évaluées ne démontre pas une couverture supérieure : il adopte le comportement exact que la littérature identifie comme le plus coûteux pour la crédibilité à long terme.
Quand les sources certifiées manquent
Modèle
% domaines uniques
% domaines uniques lorsque Vera n'a pas trouvé de réponse
ChatGPT
54.9
65.3
Gemini
76.1
86.3
Perplexity
79.5
88.0
Lorsqu'on isole les questions auxquelles Vera n'a pas trouvé de sources suffisantes pour répondre, c'est-à-dire précisément les cas où l'information n'a pas encore été vérifiée par une source certifiée, la proportion de domaines uniques augmente systématiquement chez les trois LLMs : elle passe de 54.9% à 65.3% pour ChatGPT, de 76.1% à 86.3% pour Gemini, et de 79.5% à 88% pour Perplexity. L'écart n'est pas marginal : il atteint plus de dix points pour ChatGPT et Gemini. Autrement dit, c'est précisément là où les sources fiables manquent que les LLMs s'appuient le plus massivement sur des domaines uniques, des domaines sur lesquels le système ne dispose d'aucun historique de fiabilité. Ce résultat confirme deux constats formulés plus haut. D'une part, la diversité des domaines cités ne reflète pas une stratégie de triangulation des sources mais le fonctionnement du moteur de recherche sous-jacent, qui remonte ce qui est disponible et bien référencé à l'instant donné, indépendamment de toute évaluation éditoriale. D'autre part, les LLMs répondent quel que soit le niveau de confiance que leurs sources autorisent : là où Vera s'abstient faute de matériau vérifiable, ils produisent une réponse adossée, dans le cas de Perplexity, à près de neuf domaines sur dix qui n'apparaissent nulle part ailleurs dans d’autres cas de fact-checking.
Ce résultat confirme le constat d'ensemble : ce n'est pas le nombre de sources qui fait la fiabilité d'un fact-check, mais les critères qui président à leur sélection.
Conclusions préléminaires
Les résultats convergent avec un corpus croissant de travaux montrant que les fournisseurs de LLMs ne constituent pas, en l'état, des outils fiables pour le fact-checking. Leur architecture, un modèle de langage couplé à un moteur de recherche généraliste, n'est pas conçue pour évaluer la fiabilité des sources qu'elle mobilise, mais pour produire une réponse fluide et documentée en apparence.
La distribution des types de sources observée dans nos données, prédominance de domaines commerciaux, présence significative de réseaux sociaux, peu de sources académiques et gouvernementales, s'inscrit dans le prolongement direct des analyses à grande échelle [27, 28].
Si l’on ajoute que la recherche a démontré que l’association des réponses et des citations pouvait être de mauvaise qualité ou très incertaine, les capacités du fact-checking de ces LLMs semblent grandement limitées [29, 30]. Vera se distingue des LLMs commerciaux non par une supériorité technologique abstraite, mais par des choix méthodologiques qui répondent directement aux exigences du fact-checking : un répertoire de sources préalablement évaluées par des organismes de labellisation indépendants (JTI, EFCSN, IFCN), une classification explicite du niveau de fiabilité des références mobilisées, et, comme nous l'avons montré, la capacité de ne pas répondre lorsque les sources disponibles ne permettent pas de produire une vérification fiable. Cette dernière propriété n'est pas un défaut de couverture : c'est la condition même de la crédibilité d'un outil de vérification. Dans un domaine où la confiance de l'utilisateur dépend de la calibration entre certitude affichée et solidité des fondements, un système qui reconnaît ses limites protège mieux cette confiance qu'un système qui répond systématiquement, quelles que soient les sources sur lesquelles il s'appuie. Les deux axes d'analyse que nous avons retenus, la catégorisation des sources mobilisées et la mesure de leur rareté dans le corpus, confirment cette lecture de manière complémentaire : le premier révèle la nature de ce que les modèles citent, le second la stabilité de ce qu'ils citent. Ensemble, ils montrent que les LLMs ne manquent pas de sources, ils manquent de critères pour les choisir.